
Überblick
Nicht jede Anwendung oder Umgebung ist für die Anforderungen schlanker, stark verteilter Workloads ausgelegt. Edge Computing ist Computing, das bei oder in der Nähe von Nutzenden oder Datenquellen stattfindet, also außerhalb der traditionellen, zentralisierten Rechenzentren/Clouds. Dies gilt für ein ganzes Spektrum von Infrastrukturarchitekturen. Einerseits gibt es preiswerte, tragbare Geräte am äußeren Netzwerkrand mit begrenzten Rechenressourcen (zum Beispiel mobile Edge-Computing-Geräte wie Smartphones und Handheld-Tablets); IDC nennt dies „Light Edge". Das andere Ende des Spektrums, der „Heavy Edge", lässt sich mit der Konfiguration eines Rechenzentrums/einer entfernten Niederlassung mit großen Servern und zahlreichen Nutzenden (und Datentransaktionen) vergleichen.
Unabhängig davon, wo sich Ihre Infrastruktur innerhalb dieses Spektrums einordnen lässt, gibt es einige gemeinsame Anforderungen und Erwartungen. Im Kern müssen Nutzende und Geräte in der Lage sein, Transaktionen in Echtzeit durchzuführen, um Kundenerwartungen und Performance Service Level Agreements (SLAs) erfüllen zu können. Das bedeutet, dass effektive Anwendungen in diesen Umgebungen in der Lage sein müssen, ganz bestimmte Performance Benchmarks zu erreichen. Derartige Anwendungen werden als latenzempfindliche Anwendungen bezeichnet.
Definition einiger Begriffe
Zunächst sollten wir die grundlegenden Begriffe definieren, bevor wir uns mit der Frage beschäftigen, was latenzempfindliche Anwendungen sind:
- Latenz ist die Zeit zwischen dem Auftreten eines Ereignisses und der Verarbeitung dieses Ereignisses durch ein System. Am einfachsten lässt sie sich mit der Zeit vergleichen, die man braucht, um von Punkt A nach Punkt B zu gelangen.
- Bandbreite (oder Netzwerkbandbreite) ist die Datenmenge, die innerhalb eines bestimmten Zeitraums übertragen werden kann. Sie wird in der Regel in Megabit oder Gigabit pro Sekunde angegeben. Die tatsächlich in einer bestimmten Zeit übertragene Datenmenge wird als Durchsatz bezeichnet. Hohe Bandbreite (oder hoher Durchsatz) und niedrige Latenz können manchmal als Kompromiss betrachtet werden. Es ist schwierig, beides gleichzeitig zu erreichen.
- Pakete sind die zu übertragenden Datenelemente.
- Jitter ist eine Varianz bei der Latenz, die in der Regel dann auftritt, wenn die Konsistenz der Netzwerkkommunikation unterbrochen oder zeitweise langsam ist.
- Echtzeit bedeutet, dass ein Vorgang innerhalb einer bestimmten, definierten Zeitspanne (normalerweise in Milli- oder Mikrosekunden gemessen) durchgeführt wird. Echtzeit wird oft als „wirklich schnell" missverstanden. Echtzeit bedeutet vielmehr Determinismus, d. h., dass der Vorgang unabhängig von anderen Vorgängen oder der Last innerhalb einer bestimmten Zeitspanne garantiert wird. Bei der Echtzeitverarbeitung sind Transaktionen einzeln zu betrachten, im Gegensatz zur Batch-Verarbeitung, bei der mehrere Transaktionen zusammengefasst werden.
- Edge-Knoten beziehen sich im Allgemeinen auf Geräte oder Server, auf denen Edge Computing stattfinden kann.
Was sind latenzempfindliche Anwendungen?
Die Latenz ist eine zeitbasierte Metrik, die die tatsächliche Antwortzeit eines Systems im Vergleich zur geplanten Antwortzeit misst. Dabei wird in der Regel die Performance des Netzwerks, der Hardware, der Firmware und des Betriebssystems bewertet, und zwar sowohl einzeln als auch insgesamt für das gesamte System. Für latenzempfindliche Anwendungen ist eine niedrige Latenz von Vorteil, da sie bedeutet, dass die Verzögerung zwischen der Einleitung eines Vorgangs und der daraus resultierenden Antwort kurz ist. Eine höhere Latenz ist schlecht, weil sie langsamer ist und je nach Datentyp bedeuten kann, dass Pakete ausgelassen werden oder verloren gehen. Außerdem sollte die Latenz stabil sein – zu viel Jitter macht das Netzwerk unzuverlässig, auch wenn die durchschnittliche Latenz gut ist.
Ein Beispiel für eine edgebasierte, latenzempfindliche Anwendung ist ein KI-gesteuertes autonomes Fahrzeug. Der Bordcomputer hat nur Millisekunden Zeit, um zu erkennen, ob sich ein Fußgänger oder ein anderes Objekt auf der Fahrbahn befindet, und um eine Kurskorrektur vorzunehmen. Die gesamte Datenverarbeitung und die künstliche Intelligenz müssen sich im Fahrzeug befinden, zusammen mit der Live-Telemetrie, die an ein Gateway oder ein Rechenzentrum übermittelt wird. Eine langsame Reaktion bei der Verarbeitung einer Kreditkartentransaktion oder einer Videokonferenz kann für Endbenutzende frustrierend sein, aber ein Ausfall beim autonomen Fahren kann lebensbedrohlich sein. Das Institute of Electrical and Electronic Engineers (IEEE) weist auf die Abhängigkeit vieler moderner Technologien von latenzempfindlichen Anwendungen hin.
Im Allgemeinen wird die Latenz als ein Faktor der Geschwindigkeit betrachtet, aber eigentlich ist die Latenz eher ein Aspekt der gesamten Systemperformance. Die Latenz ist die Zeit zwischen dem Beginn eines Ereignisses und seiner Beendigung. Und diese Zeitlimits können je nach Anwendung flexibel sein. Das autonome Fahrzeug ist ein Beispiel für ein hartes Zeitlimit: Die Verarbeitung muss sofort erfolgen, sonst könnte es zu kritischen Systemausfällen kommen.
Manche Workloads erfordern keine niedrige Latenz. Anders ausgedrückt: Die Zeitspanne zwischen Auslösung und Reaktion auf eine Operation kann vertretbar lang sein. Diese Workloads sind asynchron, d. h. die Zeit zwischen dem Beginn und der Beendigung ist für die Nutzenden nicht beobachtbar oder relevant. Eine hohe Latenz ist bei Diensten wie E-Mails akzeptabel, da die Zeit, die für den Empfang einer E-Mail nach dem Senden benötigt wird, von Endbenutzenden nicht ohne Weiteres wahrgenommen werden kann.
In komplexen Umgebungen, unabhängig davon, ob es sich um ein einzelnes System oder mehrere interagierende Systeme handelt, sind die Auswirkungen der Latenz kumulativ. Unabhängig davon, ob die Operationen sequentiell oder parallel ausgeführt werden müssen, kann die Effektivität des gesamten Systems durch die Gesamtlatenz der zentralen Operationen beeinflusst werden. In diesem Fall ist die Geschwindigkeit vielleicht nicht der vorherrschende Faktor, sondern die Konsistenz ist die Hauptmetrik. Dies wird als deterministische Latenz bezeichnet, d. h. die erwartete Latenz für eine bestimmte Operation (oder die Gesamtlatenz für sämtliche Operationen) ist vorhersehbar und konsistent. Dies kann von entscheidender Bedeutung sein, wenn mehrere Geräte synchronisiert werden müssen, beispielsweise phasengesteuertes Radar (Phased-Array-Radar), Telekommunikationsgeräte oder Produktionsanlagen.
TLDR: Eine latenzempfindliche Anwendung ist funktionell eine Echtzeitanwendung. Dabei kann es sich um Anwendungen handeln, bei denen eine hohe oder variable Latenz die Performance der Anwendung negativ beeinträchtigen, sodass die Operationen innerhalb eines deterministischen Zeitfensters ablaufen müssen, das oft in Mikrosekunden gemessen wird. Diese Anwendungen werden auch als Anwendungen mit niedriger Latenz bezeichnet.
Die Charakterisierung von Anwendungen als latenzempfindliche Anwendungen, bei denen die Latenz die Performance beeinträchtigt, die Anwendung aber noch funktioniert, und als latenzkritische Anwendungen, bei denen eine Latenz ab einem bestimmten Punkt zu einem Ausfall führt, kann von Vorteil sein.
Latenz, Virtualisierung und Cloud-Services
Latenz wird häufig in Bezug auf die Performance des Netzwerks beschrieben, aber latenzempfindliche Anwendungen machen deutlich, dass die Netzwerkqualität häufig nicht die einzige Ursache für die Latenz ist. Faktoren, die die Verarbeitungszeit beeinflussen, wirken sich auch auf die Latenz aus.
Bei Virtualisierung und virtuellen Maschinen konkurrieren verschiedene virtuelle Prozesse miteinander um CPU-Ressourcen und gemeinsam genutzte Ressourcen wie Arbeitsspeicher und Storage. Selbst Systemeinstellungen wie die Energieversorgung und die Transaktionsverarbeitung können sich darauf auswirken, wie verschiedene Prozesse auf Ressourcen zugreifen.
Ähnliche Herausforderungen können bei Cloud-Computing-Umgebungen auftreten. Je mehr Abstraktionsschichten es in der Hardwareumgebung gibt, desto schwieriger kann es sein, die Verarbeitung und die gemeinsam genutzten Ressourcen so zuzuweisen, dass die Verarbeitungszeit optimiert und die Latenz für Kernanwendungen minimiert wird. Cloud-Anbieter wie Amazon Web Services (AWS) können Deployments und Optimierungen für latenzempfindliche und latenzkritische Anwendungen anbieten.
Bei einer latenzempfindlichen Anwendung sind die allgemeine Betriebsumgebung und die zugrunde liegende Hardware ebenso wichtig für die Zuverlässigkeit wie die Netzwerkinfrastruktur und -konfiguration.
Die Rolle latenzempfindlicher Anwendungen im Edge Computing
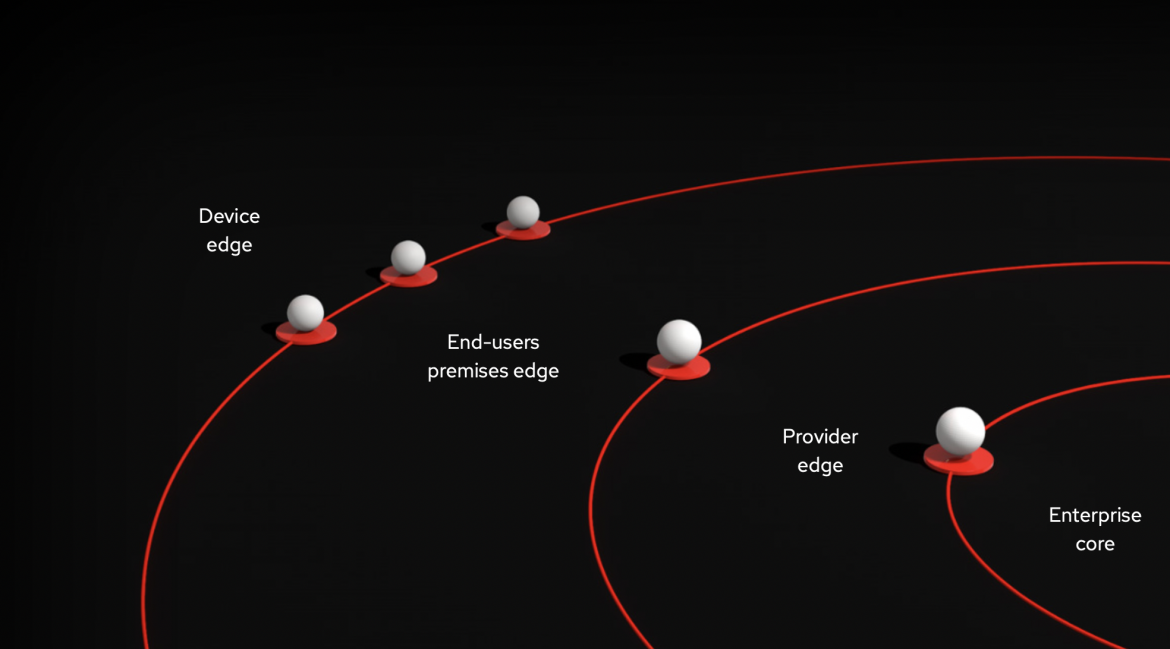
Eine Edge-Architektur wird oft wie eine Art Zwiebel beschrieben, mit konzentrischen Kreisen von Hardwareschichten, die sich immer weiter vom zentralen Rechenzentrum entfernen. Jede Schicht hat ihre eigene Architektur und ihre eigenen Aspekte. Für diese verschiedenen Use Cases sind unterschiedliche Lösungen erforderlich.
Die äußeren Ringe einer Edge-Architektur sind diejenigen, die den datengenerierenden Interaktionen am nächsten sind, wie beispielsweise Kunden/Nutzende oder gemanagte Geräte. Diese Edges müssen in hohem Maße auf sich verändernde Bedingungen und neue Daten reagieren können und werden daher am ehesten für latenzempfindliche oder Echtzeitanwendungen eingesetzt. Dies sind auch die Schichten, die am weitesten von gemeinsamen Datastores entfernt sind und über schlanke Hardware in kleinem Umfang wie Tablets oder IoT-Geräte (Internet of Things) verfügen.
In diesem Zusammenhang können IT-Führungskräfte effektive Prozesse und Richtlinien entwickeln, um sicherzustellen, dass ihre latenzempfindlichen Anwendungen und die gesamte Edge-Computing-Umgebung leistungsfähig bleiben. Diese sollten folgende Aspekte umfassen:
- Klare, zentralisierte Entwicklungs- und Bereitstellungs-Pipelines
- Konsistente Aktualisierungs- und Verwaltungsrichtlinien für Software und Hardware
- Integration von Performance-Tests in sämtliche Pipelines
- Automatisierung soweit möglich
- Definition von Standardbetriebsumgebungen zur Gewährleistung der Konsistenz über den gesamten Netzwerkrand
- Verwendung konsistenter, offener Standards und Methoden für die Interoperabilität
Diese Best Practices sind ähnlich denen für industrielles IoT (IIoT), High-Performance Computing und andere verteilte Architekturen. Edge oder IoT sind kein Endzustand. Sie sind ein Mittel, um ein bestimmtes Ziel zu erreichen. Ebenso sind latenzempfindliche Anwendungen nicht nur deshalb von Vorteil, weil schneller besser ist. Diese Anwendungen dienen dem Zweck, durch schnelle Datenverarbeitung leistungsstarke Kundenerlebnisse zu schaffen oder große Anlagen sicher und effizient zu verwalten, auf veränderte Betriebsbedingungen zu reagieren und sich an neue Inputs anzupassen.
Wie Red Hat mit latenzempfindlichen Anwendungen umgeht
Das Betriebssystem ist in Edge- und Cloud-Umgebungen genauso wichtig wie in physischen Rechenzentren und Serverräumen. Das Betriebssystem bietet Kernfunktionen, wie Ressourcenprovisionierung und -management, die für latenzempfindliche Anwendungen entscheidend sind, sowie weitere IT-Anforderungen wie Sicherheit und Netzwerkkonfiguration.
Bei latenzempfindlichen Anwendungen stellt sich die Frage, wie viele Daten im Rechenzentrum oder in der Cloud überprüft werden müssen, oder ob die Aktivitäten lokal ausgeführt werden sollen. Dabei geht es um ein Gleichgewicht zwischen Datenmenge und Geschwindigkeit.
Wenn die Risiken der Latenz in der lokalen Verarbeitung liegen, gibt es spezielle Tools, die die Performance des Systems verbessern können. Alternativ ist es möglich, mit verschiedenen Tools und Technologien eine Architektur zu entwickeln, die die Auswirkungen der Latenz verringert.
Berücksichtigung der Latenz in der Architektur
Abhängig von Ihrem Ansatz sind Sie vielleicht mehr an den Latenzanforderungen innerhalb des Netzwerks interessiert, das heißt, dass Ihre Edge-Architektur für die effektive Ausführung Ihrer Services entscheidend ist. Angesichts der Netzwerklatenz muss Ihre Edge-Architektur in der Lage sein, Daten lokal, also am Edge, selbst zu verarbeiten, anstatt Rohdaten an ein Rechenzentrum zu senden, sie zu verarbeiten und eine Antwort zu senden. Die Möglichkeit, die Verarbeitung von Anwendungen an den Netzwerkrand zu verlagern, verringert die Abhängigkeit von Netzwerken mit hoher Latenz.
Red Hat® Enterprise Linux® for Distributed Computing bietet edgeoptimierte Funktionen zur Bereitstellung von Anwendungs-Workloads in einer verteilten Hybrid Cloud-Architektur, einschließlich Rechenzentrum, Cloud und Edge, mit einer offenen und konsistenten Betriebsumgebung. Red Hat Enterprise Linux for Distributed Computing kann auf Edge-Endpunkten und Gateways installiert werden, damit Anwendungen Daten lokal analysieren und verarbeiten und gleichzeitig relevante Updates und datenbasierte Erkenntnisse an Server in der Cloud oder im Rechenzentrum liefern können. Dies verringert die Abhängigkeit von Netzwerken mit hoher Latenz, inkonsistenter Bandbreite und unterbrochenen Verbindungen.
Umgang mit der Systemlatenz
Das Timing ist entscheidend für latenzempfindliche Umgebungen. Selbst bei gut durchdachten Architekturen kann es eine kluge Entscheidung sein, ein hochleistungsfähiges System am Netzwerkrand für die lokale Verarbeitung einzusetzen.
Latenzempfindliche Anwendungen erfordern eine hochgradig anpassbare Betriebsumgebung. Red Hat Enterprise Linux for Real Time ist ein spezielles Paket zur Implementierung von Änderungen an Algorithmen und Subsystemen, das speziell für latenzempfindliche Umgebungen entwickelt wurde, in denen die Anforderungen hinsichtlich Vorhersagbarkeit und Geschwindigkeit über eine normale Performance-Optimierung hinausgehen.
Red Hat Enterprise Linux for Real Time enthält Low-Level-Dienstprogramme, die wichtige Konfigurationen für eine bessere Performance in Echtzeit unterstützen:
- Optimierte Hardware- und Speicherkonfigurationen sowie Anwendungen, die mit gleichzeitigen Programmiertechniken geschrieben wurden
- Kontrollierte Ausführung von Multithreading- und Multiprozess-Anwendungen
- Prüfung der Eignung eines Hardwaresystems
- Definition des Caching-Verhaltens
Auf ein größeres IT-Ökosystem setzen
Hier ist das IT-Ökosystem von Red Hat besonders leistungsfähig. Es verfügt über zertifizierte Hardwarekonfigurationen und -anbieter für Red Hat Enterprise Linux for Real Time und Red Hat Enterprise Linux for Distributed Computing, die Ihnen die Gewissheit geben, dass Ihre Edge-Anwendungen gemäß Ihren Spezifikationen ausgeführt werden.
Darüber hinaus ist Red Hat Enterprise Linux mit Red Hat® OpenShift® für die Orchestrierung und Bereitstellung von Kubernetes-Containern, Red Hat® Ansible® Automation Platform für die Automatisierung und Red Hat Middleware für Prozess- und Entscheidungsmanagement, Daten-Streams, Integration und andere Tools integriert.
Edge ist eine Strategie, mit der Sie Insights und Erfahrungen genau dann bereitstellen, wenn sie benötigt werden. Red Hat Enterprise Linux for Real Time, Red Hat Enterprise Linux for Distributed Computing und das gesamte Red Hat Portfolio können eine leistungsstarke Basis für die Umsetzung dieser Strategie sein.


