
Red Hat OpenShift AI: Cloud-Services für KI/ML
Schnellere Entwicklung intelligenter Anwendungen
Künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) beeinflussen zunehmend die Modernisierung von Anwendungen in zahlreichen Unternehmen und Branchen. Diverse Organisationen müssen aus ihren Daten strategischen Nutzen ziehen und neue Insights gewinnen. Daher steht die Ausweitung des Einsatzes intelligenter cloudnativer Anwendungen und DevOps-Methoden im Vordergrund. Diese schöne neue Welt kann jedoch komplex sein, was sich auf sämtliche Beteiligten auswirkt: von Entwicklungsteams über Data Scientists bis hin zu Operations-Teams. Traditionelle Ansätze können Herausforderungen mit sich bringen:
- Bereits der Einstieg kann Probleme bereiten, angefangen bei der Aktualisierung und Konsistenz von sich schnell entwickelnden Tools und Anwendungsservices über die Provisionierung von Hardwareressourcen wie GPUs (Graphic Processing Units) bis hin zur Skalierung intelligenter Anwendungen.
- Gängige Cloud-Plattformen bieten Skalierbarkeit sowie attraktive, integrierte Umgebungen und Toolsets, können jedoch Nutzende mit restriktiven Toolchains und begrenzten Deployment-Optionen effektiv binden.
- Unterschiedliche Plattformen für Anwendungsentwicklung und Data Science können die Zusammenarbeit erschweren und die Entwicklungsgeschwindigkeit beeinträchtigen.
- Das Deployment intelligenter Anwendungen in großem Umfang kann schwierig sein, insbesondere wenn verschiedene Entwicklungs- und Produktionsplattformen verwendet werden.
Red Hat® OpenShift® AI (früher Red Hat OpenShift Data Science) ist ein gemanagter Cloud-Service und bietet Data Scientists und Entwicklungsteams eine leistungsstarke KI/ML-Plattform für Entwicklung und Deployment intelligenter Anwendungen. Unternehmen können mit verschiedenen Tools experimentieren, auf einer gemeinsamen Plattform zusammenarbeiten und die Markteinführung beschleunigen – und zwar auf einer zentralen Plattform. OpenShift AI kombiniert die Self-Service-Umgebung, die sich Data Scientists, Entwicklerinnen und Entwickler wünschen, mit der Zuverlässigkeit, die eine Unternehmens-IT erfordert.
Eine vertrauenswürdige Basis reduziert die Reibungsverluste im gesamten Lifecycle. OpenShift AI bietet eine robuste Plattform, ein umfassendes IT-Ökosystem gängiger zertifizierter Tools und vertraute Workflows für das Deployment von Modellen in der Produktion. Mit diesen Vorteilen können Teams reibungsloser zusammenarbeiten und intelligente Anwendungen effizienter auf den Markt bringen, was letztlich einen höheren Mehrwert für das Unternehmen schafft.
Beschleunigte Entwicklungs-, Trainings-, Test- und Deployment-Prozesse
OpenShift AI (früher OpenShift Data Science) basiert auf dem Community-Projekt Open Data Hub und dem „Operate First“-Prinzip. Open Data Hub bildet eine KI/ML-Plattform auf Red Hat OpenShift mit Upstream-Projekten wie Apache Kafka und Kubeflow. Durch das „Operate First“-Prinzip basieren Operationen auf Open Source-Konzepten, sodass Entwicklungs- und Operations-Teams zusammenarbeiten und für operative Exzellenz sorgen können, ohne an proprietäre Tools gebunden zu sein. OpenShift AI stellt einen Teil der Tools von Open Data Hub in einem vollständig unterstützten Cloud-Service zur Verfügung, gemanagt auf Amazon Web Services (AWS), mit optionalen Angeboten von unabhängigen Softwareanbietern (ISV).
Experimentieren mit ausgewählten Tools
Mit OpenShift Data AI können Data Scientists experimentieren und neue Wege entdecken, Insights in das Unternehmen einzubringen. Da es sich um einen vollständig gemanagten Cloud-Service handelt, können Data Scientists Modelle für maschinelles Lernen entwickeln, trainieren und testen, bevor sie bereitgestellt werden. Teams erhalten Zugriff auf fortschrittliche Tools im Rahmen eines integrierten IT-Erlebnisses. Data Scientists können ihre vertrauten Tools verwenden oder auf ein wachsendes Technologiepartnernetzwerk mit breit aufgestellter KI/ML-Expertise zugreifen – ohne Bindung an eine vorgeschriebene Toolchain. Statt darauf zu warten, dass die IT-Abteilung die erforderlichen Ressourcen bereitstellt, erhalten sie die On-Demand-Infrastruktur mit einem Klick, statt mit einem IT-Ticket.
Zusammenarbeit auf einer gemeinsamen Plattform
OpenShift Data AI basiert auf einer Open Source-Architektur, die sowohl für ML-Workloads als auch für Entwicklungs-Workflows konzipiert wurde. Dadurch werden die Lücken zwischen Data Science und DevOps verkleinert und der Aufwand durch Handoffs auf dem Weg zur Produktion verringert. Data Scientists arbeiten in Echtzeit in Jupyter Notebooks zusammen. Entwicklungsteams integrieren containerfähige Modelle mit weniger Reibungsverlusten in intelligente Anwendungen. Die IT-Abteilung muss sich weniger um die Governance kümmern und keine verdächtigen Cloud-Plattformkonten aufspüren.
Beschleunigte Markteinführung für intelligente Anwendungen
Mit OpenShift AI können Sie ML-Modelle aus frühen Pilotprojekten auf einer gemeinsamen, konsistenten Plattform schneller in intelligente Anwendungen integrieren. Data Scientists können umgehend mit den Tools ihrer Wahl beginnen und auf Self-Service-Infrastruktur zugreifen. Dank eines Software-Partnernetzwerks mit zahlreichen zertifizierten Tools und umfassendem KI/ML-Fachwissen verbindet der Service sämtliche Phasen des ML-Lifecycles mit tiefgehenden KI-Funktionen. Sie können Modelle in Hybrid Cloud-Umgebungen bereitstellen und erhalten so die Flexibilität, Workloads dort auszuführen, wo Sie gebraucht werden, ohne an eine kommerzielle Cloud gebunden zu sein.
OpenShift AI
Abbildung 1 zeigt, wie sich der Modelloperations-Lifecycle mit dem anfänglichen Angebot von OpenShift AI (früher OpenShift Data Science) als gemeinsame Plattform integrieren lässt. Dieser Cloud-Service ist über Red Hat OpenShift Dedicated (auf AWS) und Red Hat OpenShift Service on AWS verfügbar. Er bietet einen zentralen Data Science-Workflow als gemanagter Red Hat Service mit der Möglichkeit für erweiterte Funktionen und Zusammenarbeit durch ISV-zertifizierte Software. Modelle werden entweder in OpenShift Cloud Service gehostet oder zur Integration in eine intelligente Anwendung exportiert.
Highlights
- Entwicklung mit den Tools Ihrer Wahl, ohne Sorge um die Infrastruktur.
- Weniger Reibungsverluste sowie Zusammenarbeit auf einer gemeinsamen Plattform, um Data Scientists, Entwicklungs- und IT-Operations-Teams zu vereinen.
- Beschleunigung der Bereitstellung intelligenter Anwendungen und Verkürzung der Markteinführungszeit.
- Unterstützung der Data Scientists, indem sie verschiedene Anwendungen und Services aus einem umfangreichen Partnernetzwerk auswählen können.
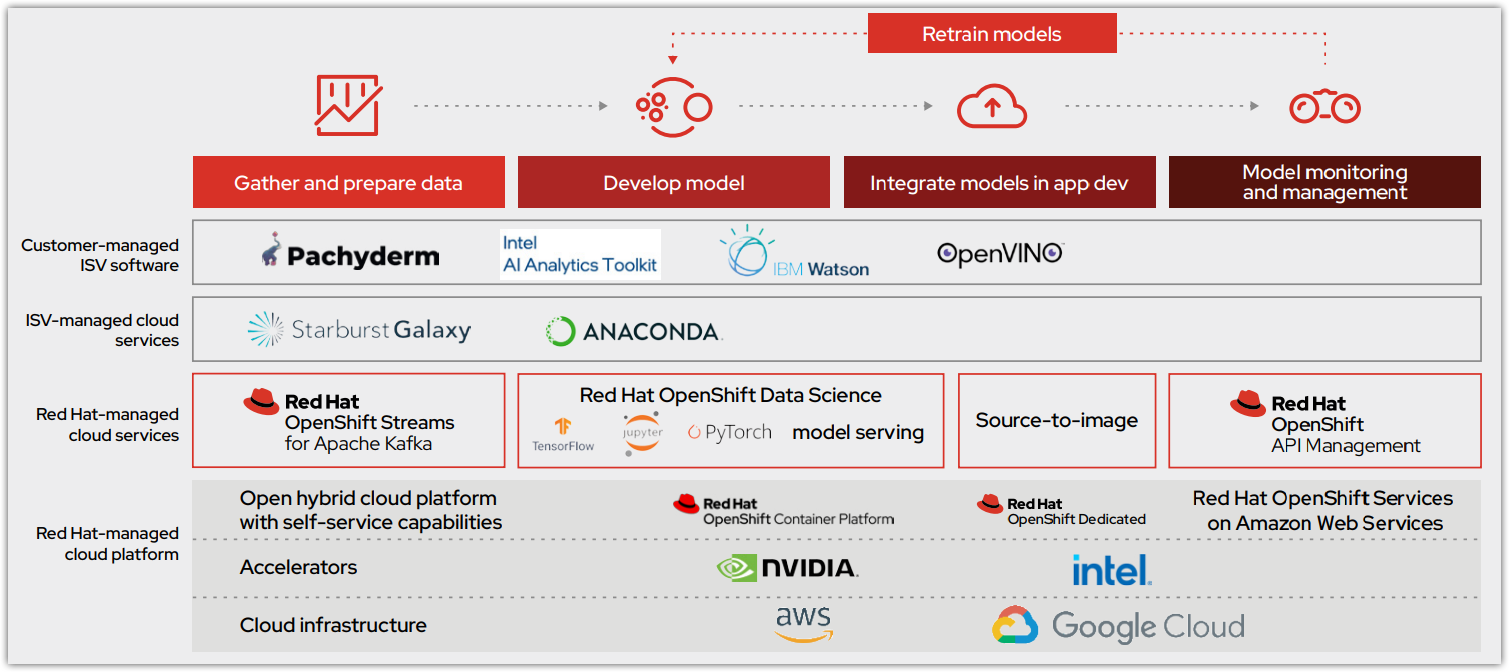
Die mit OpenShift AI bereitgestellten zentralen Tools und Funktionen bieten eine solide Grundlage:
- Jupyter Notebooks: Data Scientists können explorative Data Science-Aufgaben in JupyterLab mit Zugriff auf zentrale KI/ML-Libraries und -Frameworks wie TensorFlow und PyTorch ausführen.
- Source-to-image (S2I): Modelle können über S2I als Endpunkte zur Integration in intelligenten Anwendungen veröffentlicht und auf der Basis von Änderungen am Quell-Notebook neu aufgebaut und bereitgestellt werden.
- Optimierte Inferenz: Deep Learning-Modelle können in optimierte Inferenz-Engines konvertiert werden, um Experimente zu beschleunigen.
Red Hat stellt Jupyter Notebook Images für Tensorflow und PyTorch als Teil des Service bereit. So müssen Teams nicht bei Null anfangen, und die Nutzung dieser leistungsstarken Technologien wird für Teams weniger komplex. Für Konsistenz und Flexibilität kann der Jupyter-Spawner die benutzerdefinierten Images einer Organisation für die Data Science-Teams bereitstellen und dabei bevorzugte Libraries, Tools und Sprachen integrieren. Der Service umfasst auch das Git-Plugin für JupyterLab, sodass die Integration mit Git direkt über die JupyterLab-Schnittstelle weniger Zeit in Anspruch nimmt. Weitere gängige Analysepakete, die im Rahmen des Service bereitgestellt werden, vereinfachen den Betrieb und erleichtern den Einstieg in die geeigneten Tools für Ihr Projekt, darunter Pandas, scikit-learn und NumPy.
Da es sich um einen gemanagten Cloud-Service handelt, bietet Red Hat SRE-Support (Site Reliability Engineering) für die zugrunde liegende OpenShift-Anwendungsplattform und den OpenShift AI Service. Durch diesen Support können Sie sich auf Ihre Geschäftsanalysen konzentrieren, statt sich mit der zugrunde liegenden Plattform auseinanderzusetzen. Red Hat sorgt für eine hohe Verfügbarkeit des Red Hat OpenShift AI Service, einschließlich der zugrunde liegenden gemanagten Red Hat OpenShift Cloud-Serviceumgebung. Updates, Upgrades und Kompatibilität werden als Teil des Service gemanagt. So entfällt die Notwendigkeit, potenziell komplexe Kompatibilitätsmatrizen zwischen Analysetools zu verfolgen.
Tools für den gesamten Modell-Lifecycle
OpenShift AI bietet die Services und die Softwareprodukte, mit denen Unternehmen ihre Modelle erfolgreich bereitstellen und in die Produktivumgebung verschieben können (Abbildung 2). Dieser Prozess ist zusätzlich zu OpenShift AI in Red Hat OpenShift API Management integriert.

Das Red Hat OpenShift AI Dashboard erleichtert die Einführung und bietet einen zentralen Ort, an dem Sie sämtliche Anwendungen und die Dokumentation entdecken sowie darauf zugreifen können. Smart Start-Tutorials bieten Best Practice-Anleitungen für gängige Komponenten und integrierte Partnersoftware. Sie sind direkt über das Dashboard verfügbar, damit Data Scientists schneller lernen und loslegen können. In den folgenden Abschnitten werden die wichtigsten in Red Hat OpenShift AI enthaltenen Analysetools beschrieben.
Starburst
Starburst beschleunigt Analysen, indem es Ihren Teams die schnelle und einfache Nutzung Ihrer Daten ermöglicht, um Prozessabläufe im Unternehmen zu verbessern. Starburst wird als selbst gemanagtes Produkt oder als vollständig gemanagter Service bereitgestellt. Es demokratisiert den Datenzugriff und bietet Daten-Consumers umfassendere Insights. Das Tool basiert auf Open Source Trino (früher bekannt als PrestoSQL), der ersten MPP-SQL-Engine (Massively Parallel Processing). Starburst wurde von Expertinnen und Experten von Trino und Presto entwickelt und wird von ihnen betrieben. Mit diesem Tool können Sie flexibel verschiedene Datensätze unabhängig vom jeweiligen Speicherort abfragen, ohne Ihre Daten verschieben zu müssen.
Starburst lässt sich in die skalierbaren Cloud Storage- und Computing-Services von Red Hat OpenShift integrieren und bietet eine stabile, sicherheitsorientierte, effiziente und kostengünstige Möglichkeit, Ihre Unternehmensdaten abzufragen. Vorteile sind:
- Automatisierung: Operatoren von Starburst und Red Hat OpenShift bieten automatische Konfiguration, automatische Optimierung und automatisches Management von Clustern.
- Hohe Verfügbarkeit und problemloses horizontales Skalieren: Der Red Hat OpenShift Load Balancer kann Services wie den Trino-Koordinator in einem ständig aktiven Zustand halten.
- Elastische Skalierbarkeit: Red Hat OpenShift kann den Trino-Worker-Cluster basierend auf der Abfragelast automatisch skalieren.

Anaconda Commercial Edition
Anaconda Commercial Edition bietet kuratierten Zugriff auf eine umfangreiche Reihe von Data Science-Paketen zur Verwendung in Jupyter-Projekten, wobei vorgefertigte Jupyter Images direkt über das Red Hat OpenShift Data Science Dashboard verfügbar sind. Anaconda Commercial Edition bietet Unternehmen Zugriff auf eine der bekanntesten Open Source-Paketdistributionen und -Managementerfahrungen der Welt, optimiert für die kommerzielle Nutzung, einschließlich:
- Open Source-Innovation mit mehr als 7.500 von Anaconda kuratierten Data Science- und ML-Paketen im Premium-Repository von Anaconda.
- Content Trust-Funktionen wie die Conda-Signaturüberprüfung, die Ihnen helfen, Schwachstellen und unzuverlässige Software aus Ihren Data Science- und ML-Pipelines fernzuhalten.
- Zuverlässigkeit durch SLAs (Service Level Agreements) zur Verfügbarkeit und Support, auf den Sie sich bei Produktionsabläufen verlassen können.
- Vollständige Einhaltung der Anaconda-Nutzungsbedingungen für die kommerzielle Nutzung.
IBM Watson Studio
Mit IBM Watson Studio1 können Sie mit Watson Machine Learning und Watson OpenScale KI-Modelle in großem Umfang erstellen, ausführen und verwalten. Die Plattform kombiniert Open Source-Frameworks wie PyTorch, TensorFlow und scikit-learn mit IBM und den zugehörigen Ökosystem-Tools für codebasierte und visuelle Data Science. Die Plattform funktioniert mit Jupyter Notebooks, JupyterLab, Befehlszeilenschnittstellen (CLIs) und Python-Programmiersprachen.
IBM Watson hilft bei der Operationalisierung von KI und stärkt die Zuverlässigkeit von den Grundsätzen bis in die Praxis. Transparente Prozesse geben Einblick in KI-gestützte Entscheidungen. IBM Watson ermöglicht Datenschutz, Compliance und Sicherheit in stark regulierten Branchen und unterstützt ein offenes, vielfältiges IT-Ökosystem, das den verantwortungsvollen Einsatz von KI fördert. IBM Watson Studio bietet:
- AutoAI und AutoML zum automatischen Erstellen von Modell-Pipelines, zum Vorbereiten von Daten und Auswählen von Modelltypen sowie zum Generieren und Ranking von Modell-Pipelines.
- Erweiterte Datenoptimierung zum Bereinigen und Aufbereiten von Daten mit einem grafischen Flusseditor.
- Integrierte visuelle Tools durch IBM SPSS Modeler zur schnellen Datenvorbereitung und visuellen Entwicklung von Modellen.
- Modelltraining und -entwicklung zur schnellen Erstellung von Experimenten mit optimierten Pipelines.
- Eingebettete Entscheidungsoptimierung zur Kombination prädiktiver und präskriptiver Modelle.
- Modellmanagement und Überwachung von Qualitäts-, Fairness- und Driftmetriken.
- Modellexport als Python Jupyter Notebook.

Pachyderm
Unternehmen benötigen Datenverwaltungslösungen, die unterschiedliche Vorgänge, von Laptop-Experimenten bis hin zu wichtigen Unternehmensbereitstellungen, erleichtern. Mit Pachyderm können Data Science-Teams containerisierte, datengesteuerte ML-Pipelines mit einer garantierten Datenherkunft erstellen und skalieren, die durch automatische Datenversionierung bereitgestellt wird. Pachyderm wurde zur Lösung realer Data Science-Probleme entwickelt und bietet die Datengrundlage, mit der Teams ihren ML-Lifecycle automatisieren, skalieren und gleichzeitig für Reproduzierbarkeit sorgen können. Mit Use Cases, die von unstrukturierten Daten bis hin zu Data Warehouses, Natural Language Processing, Video- und Bild-ETL, Finanzdienstleistungen und Biowissenschaften reichen, bietet Pachyderm Folgendes:
- Automatisierte Datenversionierung, die Teams eine leistungsstarke Möglichkeit bietet, den Überblick über Datenänderungen zu behalten.
- Datengesteuerte containerisierte Pipelines zur Beschleunigung der Datenverarbeitung und Verringerung der Computing-Kosten.
- Eine unveränderliche Datenherkunft, die einen festen Datensatz für Aktivitäten und Assets im ML-Lifecycle bereitstellt.
- Die Pachyderm-Konsole zur intuitiven Visualisierung Ihres Directed Acyclical Graph (DAG) und Hilfestellung beim Debuggen sowie bei der Reproduzierbarkeit.
- Jupyter Notebook-Support mit der JupyterLab Mount Extension von Pachyderm für eine Point-and-Click-Schnittstelle zu von Pachyderm versionierten Daten.
- Enterprise Administration mit robusten Tools für die skalierte Bereitstellung und Verwaltung von Pachyderm in verschiedenen Teams innerhalb der Organisation.

Beschleunigte Data Science mit NVIDIA
Skalierbare Datenverarbeitung, Datenanalyse, Training für maschinelles Lernen und Inferenz stellen äußerst ressourcenintensive Berechnungsaufgaben dar. Mit NVIDIA-Software können Sie sämtliche Aspekte der End-to-End-Data Science beschleunigen, indem die Parallelverarbeitungsfähigkeiten von GPUs genutzt werden. Die Skalierung lokaler GPU-Ressourcen oder die Konfiguration der Kubernetes-Provisionierung sollte Data Scientists nicht von der Nutzung ihrer Zeit zur produktiven Nutzung ihrer Daten ablenken.
Diverse Organisationen nutzen bereits Lösungen von NVIDIA für maschinelles Lernen und eine Vielzahl anderer Services. OpenShift Data Science reduziert die Komplexität der Einrichtung GPU-fähiger Hardware, um ressourcenintensive Data Science-Experimente zu beschleunigen. Mit OpenShift AI können Unternehmen bei Bedarf EC2-Instanzen (Amazon Elastic Computing) mit NVIDIA-GPUs einsetzen und so die Rechenressourcen je nach Bedarf vergrößern oder verkleinern.

Intel OpenVINO Toolkit
Die Intel-Distribution des OpenVINO Toolkits beschleunigt die Entwicklung und Bereitstellung leistungsstarker DL-Inferenzanwendungen auf Intel-Plattformen. Mit dem im Toolkit enthaltenen Modelloptimierer samt Laufzeit- und Entwicklungstools können Sie umfassende KI-Inferenzen erstellen, optimieren, abstimmen und ausführen.
- Entwicklung: Entwicklerinnen und Entwickler können den sogenannten „Open Model Zoo“ nutzen, um vorab trainierte und voroptimierte Open Source-Modelle zu finden, die für die Inferenz bereit sind, oder sie können ihre eigenen DL-Modelle verwenden.
- Optimierung: Der Model Optimizer kann das Modell in Zwischencode umwandeln. Daraus entsteht ein Dateienpaar, das die Netzwerktopologie beschreibt und die Gewichtungen und Bias des Modells enthält.
- Deployment: Die Inference Engine ermöglicht die universelle Ausgabe der Ergebnisse auf mehreren Prozessoren, Beschleunigern und Umgebungen („write once, deploy anywhere“).

Intel® AI Analytics Toolkit
Das Intel AI Analytics Toolkit stellt gängige Python-Tools und -Frameworks für Data Science, KI-Entwicklung und Forschung zur Verfügung, um durchgängige Data Science- und Analyse-Pipelines auf Intel-Architekturen zu beschleunigen. Die Komponenten nutzen oneAPI-Libraries für Low-Level-Rechenoptimierungen. Dieses Toolkit maximiert die Performance von der Vorverarbeitung bis hin zum maschinellen Lernen und bietet Interoperabilität für eine effiziente Modellentwicklung.
Mit dem Intel AI Analytics Toolkit können Sie:
- mit Intel-optimierten DL-Frameworks für TensorFlow und PyTorch, vorab trainierten Modellen sowie Tools mit niedriger Präzision leistungsstarkes DL-Training auf Intel XPUs bieten und schnelle Inferenz in Ihren KI-Entwicklungsworkflow integrieren.
- mit rechenintensiven Python-Paketen, Modin, scikit-learn und XGBoost, optimiert für Intel, eine Drop-in-Beschleunigung für die Datenvorverarbeitung sowie für ML-Workflows erzielen.
- direkten Zugriff auf Analysen und KI-Optimierungen von Intel erhalten, um sicherzustellen, dass Ihre Software unterbrechungsfrei zusammenarbeitet.
Fazit
Mit OpenShift AI können Unternehmen experimentieren, zusammenarbeiten und letztendlich die Entwicklung intelligenter Anwendungen beschleunigen. Der von Red Hat gemanagte cloudbasierte Add-on-Service vereinfacht und beschleunigt das Experimentieren für Data Scientists, bietet eine moderne containerisierte KI/ML-Plattform sowie den Komfort und die Skalierbarkeit von AWS. Self-Service für Entwicklungs- und Data Science-Teams beschleunigt Innovationen auf einer Anwendungsplattform, die bereits genutzt wird und auf die sich die Unternehmens-IT voll und ganz verlassen kann. Im Gegensatz zu anderen Ansätzen können Data Scientists Tools ohne restriktive Toolchain auswählen und so für neue, datenbasierte Insights sorgen – ohne unnötige Beschränkungen.
IBM Watson Studio und Watson Machine Learning sind Teil des IBM Cloud Pak for Data-Angebots.
